- Elena Fratto
- Rishi Goyal
- Arden Hegele
- Emily Madison
- Dennis Yi Tenen

Vaccine hesitancy is not simply a matter of ignorance. Communities around the country are reluctant to vaccinate for all sorts of reasons: personal, religious, political, medical. By studying the language of vaccine-related conversations online–using computational analysis–our team of data and language researchers are revealing the deep seated causes of vaccine hesitancy, with the hope of improving vaccine messaging and ultimately increasing uptake.
Language matters. When declaring a “war on drugs,” for example, one should not be surprised if the treatment of addiction becomes militarized, involving further the use of excessive force in the policing of non-violent offences. Similarly, the framing of vaccine hesitancy in terms of ignorance further implies an uneducated public, alienating those who have real concerns about vaccination: in its compliance with Halal... read more →
- Beth Cortese
- Julie Hastrup-Markussen
- Ross Deans Kristensen-McLachlan
- Jakob Ladegaard
- Dennis Yi Tenen

And now, with regard to the worldly matters which I shall die possessed of, as well as to those which of right appertain to me, either by the will of my said grandfather, or otherwise; thus do I dispose of them. – Samuel Richardson: Clarissa, Vol. 9, letter XXXIII.
The reading of the grandfather’s will in Samuel Richardson’s Clarissa sets in motion a crisis of ownership in which Clarissa’s “father’s living will” seeks to control her “grandfather’s dead one” (Vol. 1, letter XLIV). Clarissa becomes estranged from her family when she inherits an estate from her grandfather, who thereby bypasses her father and uncles as well as her siblings. The novel ends with Clarissa’s will, in which her property, guilt, and moral justice are distributed after her death. Bracketed by these two last wills, the novel can be read as a sustained reflection on the relationship between possession of property, inheritance, and agency.
In a joint effort between Columbia English Department’s Literary Modeling and Visualization Lab and the Unearned Wealth research project at the Department of Comparative Literature, Aarhus University, Denmark,... read more →
- Dennis Yi Tenen
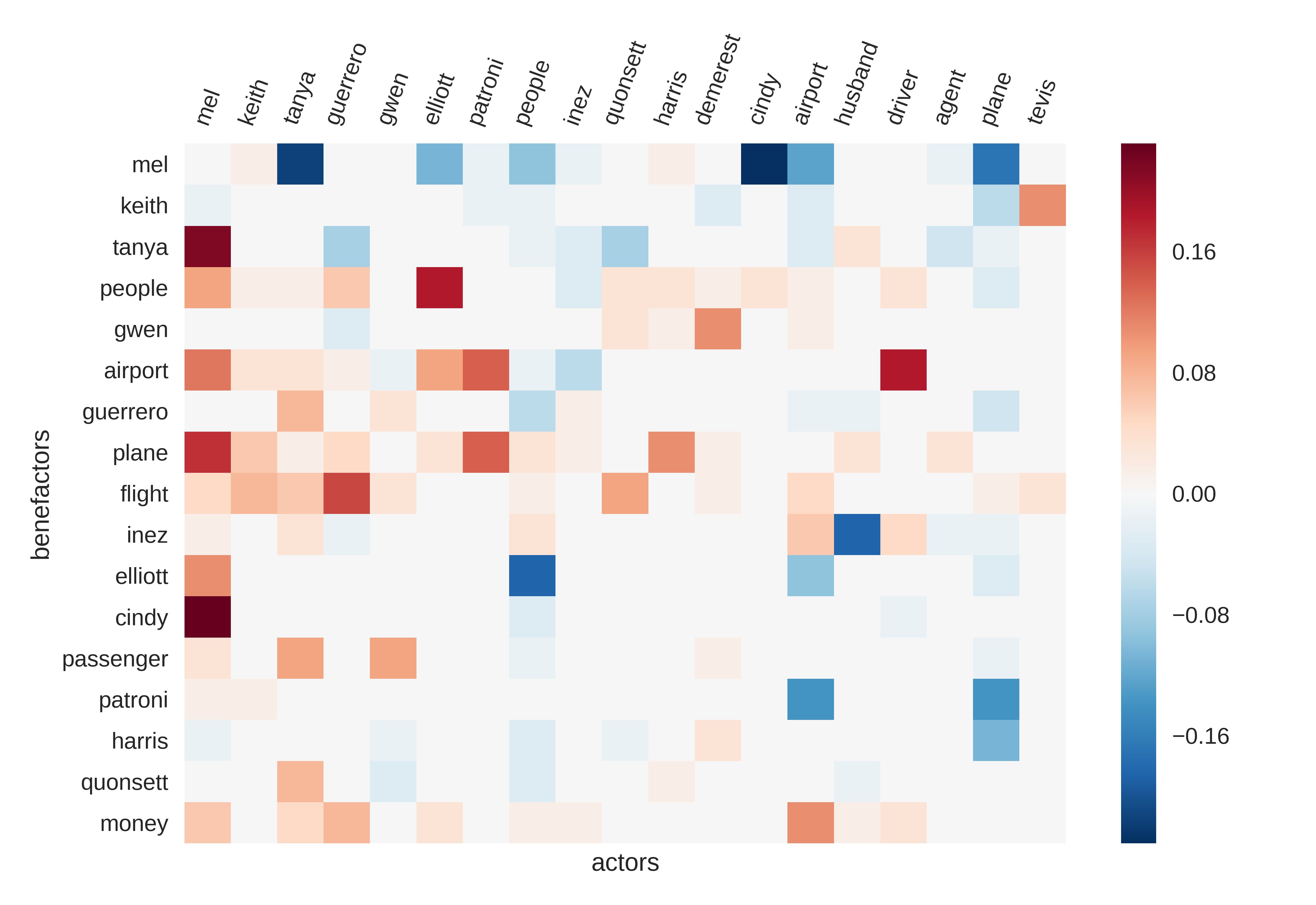
In this paper I discuss the question of institutional agency more narrowly, on the basis of a literary genre principally concerned with trans-human, organizational actors. The readings will occasion a model of agency more broadly, which besides its exploratory, theoretical potential will find its application in a method for extracting literary characters. State-of-the-art methods for detecting literary characters often rely on features such as named entities (i.e. Heathcliff), gender attributes, and evidence of direct speech or sentience.1 The house in Bleak House (1952–1853) by Charles Dickens, the wheat and the Railroad Commission in The Octopus (1901) by Frank Norris, and the airport in Arthur Hailey’s Airport (1968) are not characters by these measures. Yet we intuit them to act vitally and to exert an almost hypnotic influence on the action of the novel: “a strange beast that pertains to no one in particular and who... read more →
- Dennis Yi Tenen
Space is a hard thing to pin down. It identifies dimensional continuity and a topography, that is, a relationship between objects. It is also itself an object: a limit-defining quantity even in its most abstract sense. “O God, I could be bounded in a nutshell and count myself a king of infinite space, were it that I have bad dreams,” Hamlet says of his ambition and his dreams. A human palm can be a part of the body or a map. A mirror is a piece of furniture and a frame for reflection. Under extreme magnification, the head of a pin appears a vast and mountainous terrain, home to angels and bacterial detritus. The characterization of diegetic—let us call it also virtual and fictional—space presents further difficulties. A stretch of land in fiction measures also a stretch of the imagination. These units do not always have names or explicit boundaries. Vladimir and Estragon wait for Godot: “A country road. A tree.” Two vectors are enough to situate the world. A road gives us the X and a tree the Y axis: an infinity in a... read more →
- Dennis Yi Tenen

Literary theory can no more ignore the output of artificially intelligent agents than the study of labor can ignore the advent of robotics.
An Inquiry Concerning the Creative Limits of Artificial Intelligence is a book about the automation of labor in the literary sphere, as told through the story of writers’ aids past and present—narrative plotters, spell checkers, and language generators—the “shameful little secrets” of mass literary production.
In subsequent chapters I bring to view a number of algorithmic artifacts vital to the advance of artificial intelligence, on a spectrum from quasi-autonomous heuristics for combinatorial composition—style guides and “canned” literary formulae—to fully-autonomous bots—of the sort used to manufacture junk mail and disinformation campaigns on social media.
read more →- Gianmarco Saretto
- Jenna Alexis Schoen

In collaboration with a team of international scholars at the Open Islamicate Texts Initiative (OpenITI), our project aims to train an OCR system on a corpus of medieval manuscripts. The engine developed by OpenITI, Kraken, has a unique advantage in its line-based, rather than character-based, recognition of text, which makes it especially suitable for the density and occasional obscurity of Middle English handwriting.
We will train Kraken on a select set of manuscripts attributed to the same scribe (“Scribe D”). These include the Corpus Christi MS 198, the Plimpton MS 265, and the London Library MS V. 88. If successful, we would later train the system on an even larger set of manuscripts. Such a tool would have immense impact on medieval studies. Scholars... read more →
- Jonathan Reeve
- Milan Terlunen
- Sierra Eckert
Text reuse detection technology and approximate text matching have made possible the large-scale computational identification of intertextuality. These technologies have often been used in plagiarism detection and in studies of journalistic text reuse. Fewer studies, however, have applied these methods to humanities research. We present a method for quantifying the critical reception history of a source text by analyzing the precise location, density and chronology of its citations.
Our work builds on a recent set of digital humanities projects that use text... read more →
- Jonathan Reeve
Word histories are correlated strongly with the tone and genre of a text. When a writer chooses the word “enchantment” instead of “spell,” or “inquire” instead of “ask,” this decision may indicate, to some degree, the speaker’s mode, dialect, or level of formality. These modes may be then be measured by quantifying the aggregated etymology of an entire text. The Macro-Etymological Analyzer is a command-line utility, written in Python, that quantifies the etymologies of a text using the Etymological... read more →
- Casey Michael Henry

Finnegans Wake is a text marked by music, yet this simple fact has long been obscured by the forbidding layering of Joyce’s prose. A book that should be appreciated for its lyrical assonance and rhythms has become a notorious symbol for impenetrability and displeasure. Anyone who has heard Joyce read the “Anna Livia Plurabelle” section can appreciate the Wake’s integral aural component. Anyone appreciating Joyce’s penchant for bawdy limericks and coarse double-entendre (such as naming a book of poetry, Chamber Music, after the “music” of a chamber pot) can understand his link to unconventional music.
Roland McHugh’s Annotations to Finnegans Wake suggests a structural relationship between Joyce’s musicality and referentiality through its spatial arrangement, such that each page resembles sheet music. My project, Jail of Mountjoy, takes this sonic understanding one step further by “playing” indicative sections of these annotations as music. This is accomplished by aligning different categories of reference to respective octaves–e.g. “Professional Jargon,” “Linguistic [Taxonomic],” “Linguistic [Categorical],” and so on. Then, sections are processed through a synthesizer to allow users to hear both the level of linguistic depth and type of reference indicated, while synchronized visual animations keep one situated in the text.
See the entire project here.
read more →- Moacir P. de Sá Pereira
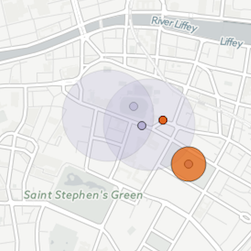
“Fabula and Sjužet in ‘Wandering Rocks’” is a data visualization of the events in the tenth episode of James Joyce’s Ulysses. It maps the events both by the fabula (historical spacetime) and sjužet (narrative spacetime) to show how both provide different points of entry into the episode.
The animation can be played both as the fabula, where events occur in chronological order, and as the sjužet, where events occur in narrative order.
The data are available to serve as a model for rebuilding the project with one’s own dataset.
read more →- Moacir P. de Sá Pereira

This python script breaks up a text into its internal sections. It uses a light markup scheme to signal where chapters and sections begin, and it also can keep track of dialogue by speaker. Given an electronic version of The Great Gatsby, for example, after the markup, it is possible to extract only Tom Buchanan’s lines.
The markup that breaks out the sections and dialogue was created by David Hoover, though the entirety of Prof. Hoover’s markup scheme has not been implemented here.
Read the README at... read more →
- Aaron Plasek
Frequently ignored and occasionally made up, the epigraph is a textual genre defined both by its physical placement on the page and by the absence of the textual object being signposted. An epigraph attribution situates the text it prefaces within a larger constellation of texts and authors, and in this manner has an indexical function rather similar to scanning the spines of books on a shelf, flipping through a card catalog, or examining a record in a digital relational database. The affordances of citation networks cannot replace other critical methods, but a comparative approach to the different kinds of citation practices made visible by different networks of attribution provides an opportunity to reconsider how shared concepts that constitute a (disciplinary) field are produced,... read more →
- Phillip R. Polefrone
This paper develops a methodology for describing the contents of a controversy on a microblogging platform (Twitter) by measuring correlations in broad semantic categories. Over one million tweets were gathered daily from November 2015 to June 2016 using Tweepy and the Twitter API, over 280,000 of which were not retweets and thus contained unique data. Using a Python implementation of Roget’s hierarchy of semantic categories, these tweets were collected in bins of one thousand and analyzed using a “bag of categories” model, or a categorized bag of words. The linear correlation of each category with the “WOMAN” category was measured and compared with a control group. The categories concomitant with “WOMAN” in the test corpus include some noise, but as a whole they present a meaningful description of the conversation that adheres to its known qualities. This result suggests that a more developed version of this methodology could be used... read more →
- Sierra Eckert
- Allison Chaney

In a novel, time does not often move evenly or linearly–––a single paragraph in García Márquez’s One Hundred Years of Solitude jumps several decades while in Proust’s In Search of Lost Time, 15 pages are devoted to a single moment of eating a madeleine. In this project, we are interested in the kind of language that used to talk about time and what is the shape and tempo of this language in a given text. Tracking what we call the “time signature” of a text, we use explicit references to time passing in order to divide up a text, and then use... read more →
- William Leif Hamilton (Stanford)
- Raine Hoover (Stanford)
- Marguerite Y. Holloway
- Dan Jurafsky (Stanford)
- David Jurgens (Stanford)
- Laura Kurgan (Center for Spatial Research)
- Minkyoung Kim (Stanford)
- Eli Bennett Levin
- Dan McFarland (Stanford)
- Vinodkumar Prabhakaran (Stanford)
- Phillip R. Polefrone
- Juan Francisco Saldarriaga (Center for Spatial Research)
- Dennis Yi Tenen
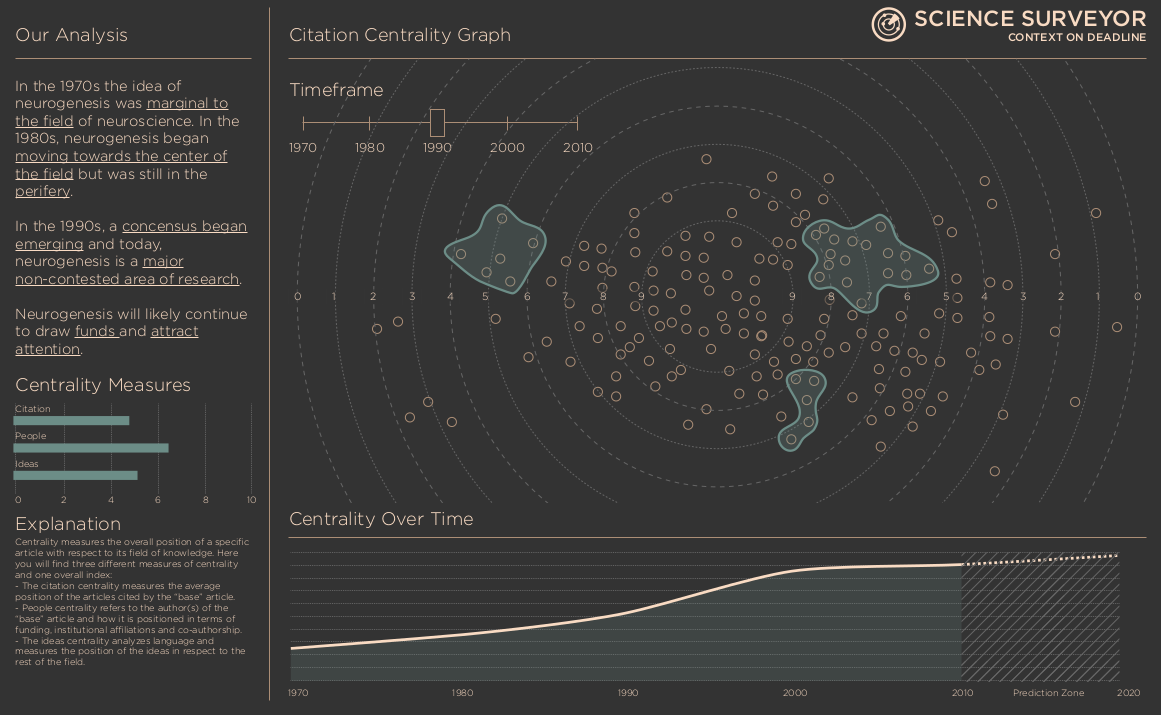
One of the biggest challenges facing science journalists is the ability to quickly contextualize journal articles they are reporting on deadline. A science reporter must rapidly get a sense of what has come before a new paper in the field, understand whether the paper represents a significant advance or not, and establish whether this finding is an outlier or part of the field’s consensus. Doing all that within a matter of hours or a few days is often impossible. The consequences of these limitations are serious and well documented. Science journalists are often overly dependent on expert sources, which encourages investigative complacency; they become vulnerable to presenting false balance and to covering articles that will be retracted; they sensationalize. As a consequence, the public often receives a mistaken view of science. Many people see science as a series of great new “discoveries” accompanied by a lot of hype; few understand... read more →
- Graham Alexander Sack

This paper models narrative as a complex adaptive system in which the temporal sequence of events constituting a story emerges out of cascading local interactions between nodes in a social network. The approach is not intended as a general theory of narrative, but rather as a particular generative mechanism relevant to several academic communities: (1) literary critics and narrative theorists interested in new models for narrative analysis, (2) artificial intelligence researchers and video game designers interested in new mechanisms for narrative generation, and (3) complex systems theorists interested in novel applications of agent-based modeling and network theory. The paper is divided into two parts. The first part offers examples of research by literary critics on the relationship between social networks of fictional characters and the structure of long- form narratives, particularly novels. The second part provides an example of schematic story generation based on a simulation of the structural balance network model. I will argue that if literary critics can better understand sophisticated narratives by extracting networks from them, then narrative intelligence researchers can benefit by inverting the process, that is, by generating narratives from... read more →
- Emily Fuhrman

In reference to schemas for Ulysses, Joyce describes the compositional technique behind the “Sirens” episode as a “fugue with all musical notations,”1 and as including the “eight regular parts of a fuga per canonem.”2 Joyce uses the first 63 lines of the chapter to introduce 99 words and syllables that reappear in different forms throughout the rest of the text. The sounds ultimately act as leitmotifs, evoking the sensory presence of different characters at different times.
This visualization is constructed as a line-by-line annotation of each sound that recurs at least four times following its... read more →
- Phillip R. Polefrone
Following Klingenstein, Hitchcock, and DeDeo (2014)’s work on the “Old Bailey” records,1 Roget Tools is a Python class for tracking broad semantic categories through bodies of text using the top-down hierarchical structure of Peter Mark Roget’s Thesaurus.2 This hierarchy is a comprehensive and unbroken network encompassing all of Roget’s original thesaurus categories, and importing it into a Python-readable format achieves two goals. First, it enables the body of research on Roget’s thesaurus to incorporated into automated text analysis, thus providing a basis for stable interpretation of quantitative results. Second, it... read more →
- Dennis Yi Tenen
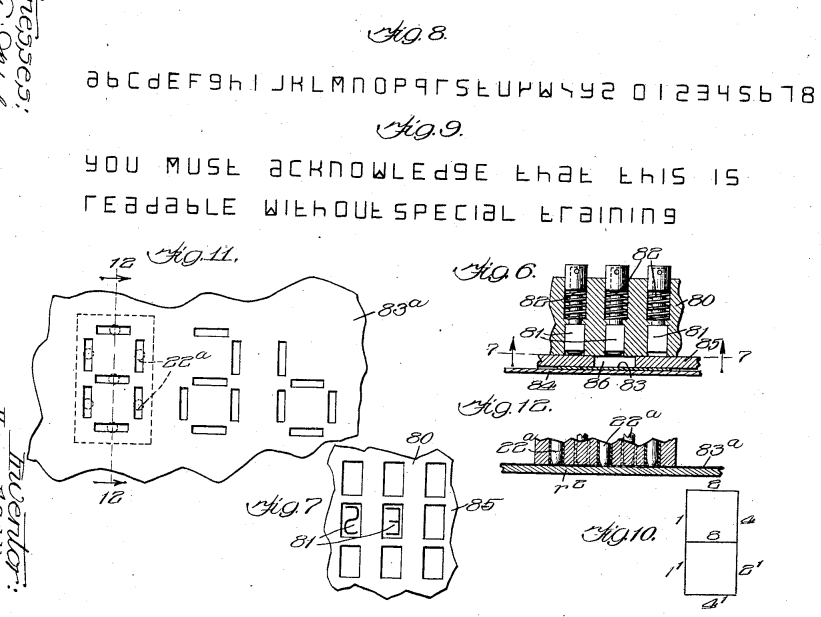
While I write these introductory remarks, a ceiling-mounted smoke detector in my kitchen emits a loud noise every three minutes or so. A pleasant female voice announces also “low battery.” This is, I learn, a precaution stipulated by US National Fire Alarm Code 72-108 11.6.6 (2013). The clause requiring a “distinct audible signal before the battery is incapable of operating” is encoded into the device. The smoke detector literally embodies that piece of legislation in its circuitry. We thus obtain a condition where two meanings of code—as governance and machine instruction—coincide. Code equals code.
I am at home, but I also receive a notification of the alarm on my mobile phone. Along with monitoring apps that help make my home “smarter,” the phone contains most... read more →
- Dennis Yi Tenen
- Susana Zialcita
This project was inspired by Christian Marclay’s The Clock1 Each minute, the LITclock Twitter handle will tweet one minute in time from a novel or narrative non-fiction book. (Occasionally, a travel guide chimes in.) Each tweet will be a quote from a book, describing what is happening in that very minute.
For example, the LIT CLOCK started with a quote from Christopher Marlowe, at precisely 12:00 am on 3/13/14:
The clock striketh twelve O it strikes, it strikes! Now body, turn to air
and then thirteen hours and nine minutes later, the LIT CLOCK told us that Miriam Wu from Stieg Larsson’s Millennium Trilogy is being interviewed:
“The time is 1:09 pm.” She turned off tape recorder.
Our goal was to create, as Zadie Smith said of Marclay’s clock, “thousands of fictional interpretations of time repurposed to... read more →